文字コードとは?Webページにおける文字コードと文字化けについて解説します
文字コードとは、アルファベットや漢字などの文字をコンピュータが扱える数値(バイナリデータ)として表現するための規則です。たとえば、ASCIIでは「A」が65として表されます。一方で、どの文字にどのコードを割り当てるかは文字コードの種類(例: ASCII, Shift_JIS, UTF-8)によって異なります。 HTML 文書では、文字コードを指定する必要があります。また HTML 文書を作成する際には、ファイルを保存する際に指定した文字コードと一致している必要があります。もし HTML 文書内で指定した文字コードと、実際に保存された文字コードが一致していない場合、文字化けが発生することがあります。この記事では Web ページで使用される文字コードの基本と、文字化けの原因について解説します。
(Last modified: )
文字コードとは
コンピュータの世界では、すべてのデータは 1 と 0 の値に置き換えられて保存されます。文字や記号が含まれる文書をファイルに保存するときも、それぞれの文字はいったん数値に置き換えなければなりません。そのため、文字とコードの対応表が作成され、この対応表をもとに文字や記号がバイナリ形式( 1 と 0 の組み合わせ)で保存されます。この対応表が文字コードです。
文字コードは数多くの種類があります。その中の一部について簡単にご紹介します。
ASCII
ASCII(American Standard Code for Information Interchange)は、文字や記号をコンピュータが扱える数値に変換するために設計された最も基本的な文字コード規格の一つです。 1960 年代に開発され、現在も一部の用途で広く使用されています。
ASCII が対応する文字セットは英語圏で使われる文字を中心に、アルファベット、数字、一部の記号(例: @, #, $, &)、制御文字(例: 改行(LF)、タブ(TAB)など)をカバーしています。ただし、日本語やアラビア文字などは含まれていません。
ASCII は 7 ビットの文字コードで、 128 種類( 0~127 のコードポイント)の文字を表現します。たとえば、アルファベットの大文字 A は 65 、小文字 a は 97 として表現されます。また、数字の 0~9 は 48~57 のコードポイントで表されます。
ISO-8859-1 (Latin-1)
ISO-8859-1(別名: Latin-1 )は、西ヨーロッパの言語を表現するために設計された文字コード規格です。 ISO(国際標準化機構)によって定義され、 ASCII で表現できる英数字や記号に加え、アクセント付きの文字や西ヨーロッパ特有の特殊記号を追加した形で設計されています。
ISO-8859-1 では ASCII(0~127)の文字セットをそのまま含んでおり、 ASCII で対応できない文字を 128~255 の範囲に追加しています。例えば、e(コードポイント233)や u(コードポイント252)などの文字がこの範囲に含まれます。この文字コードでは、 1 文字を 8 ビット( 1 バイト)で表現し、合計 256 文字を定義しています。
ISO-8859-1は、西ヨーロッパで使われる英語、ドイツ語、フランス語、など多くの言語に対応しています。アクセント付きのアルファベット(例: e, u, n)や特殊記号(例: c, £, \)も対応しています。ただし、フィンランド語やエストニア語で使用される文字は含まれておらず、一部の言語では完全に対応できない場合があります。
現在は UTF-8 が主流となっていますが、古い Web システムや一部のデータベース(例: MySQL のデフォルト設定)では依然として ISO-8859-1 が使用されている場合があります。新規プロジェクトでは UTF-8 が推奨されます。
Shift_JIS
Shift_JIS(シフトJIS)は、日本語の文字をコンピュータ上で扱うために設計された文字コードの一つです。 ASCII で表現される英数字や記号に加え、日本語のひらがな、カタカナ、漢字を表現できるように拡張されました。 1980 年代にマイクロソフトと日本工業規格( JIS )によって策定され、日本のパーソナルコンピュータや Windows 環境で広く使用されてきました。
Shift_JIS は、 ASCII(0x00~0x7F)と互換性があるため、英数字や一部の記号はそのまま表現できます。英数字や記号は 1 バイト、日本語の漢字やひらがな、カタカナは 2 バイトで表現されるため、 1 バイトと 2 バイトを組み合わせた可変長エンコーディング方式を採用しています。
Shift_JIS は基本的に日本語専用の文字コードであり、他の言語(例: 中国語や韓国語)には対応していません。現代の Web 環境では国際化や多言語対応が進み、 Shift_JIS の利用は減少しています。
EUC-JP
EUC-JP(Extended Unix Code for Japanese)は、日本語を表現するために設計された文字コードの一つです。主に Unix/Linux 環境で採用され、日本語の漢字、ひらがな、カタカナ、および ASCII 文字を効率的に扱うことができます。特に新聞社や出版業界のシステムで広く使用されました。
EUC-JP は ASCII(0x00~0x7F)と互換性があるため、英数字や一部の記号はそのまま表現できます。文字のエンコーディングは可変長で、 ASCII 文字は 1 バイト、 JIS X 0208 の文字(ひらがな、カタカナ、漢字)は 2 バイト、 JIS X 0212 の補助漢字は 3 バイトで表現されます。このため、 EUC-JP は日本語を中心とした文字セットを効率的に扱える設計となっています。
ただし EUC-JP は日本語専用の文字コードであるため、他言語(例: 中国語、韓国語、アラビア語)には対応していません。国際化や多言語対応が主流の現代のシステムや Web 環境では使用が減少しており、 UTF-8 が主流となっています。
UTF-8
UTF-8(Unicode Transformation Format 8-bit)は、世界中の文字を表現できる Unicode をエンコードするための方式の一つです。他にも UTF-16 や UTF-32 といった方式がありますが、 UTF-8 は特に効率的で汎用性が高いため、現在 Web や多言語対応システムで最も広く使用されています。
UTF-8は実際には文字コードではなく、 Unicode で定義された文字のコードポイントをバイト列に変換して保存するためのエンコーディング形式の一つです。 Unicode では、文字ごとに固有のコードポイントが定義されています。UTF-8は、このコードポイントを1~4バイトのバイト列に変換する方法を提供します。ただし、他の文字コード(例: ASCIIやShift_JIS)と同じように「文字コード」と呼ばれることがあり、文脈によっては同義として扱われることもあります。
ASCII や Shift_JIS では文字とバイト値が直接対応しており、エンコーディング形式が分離していません。そのため、これらは「文字コードとエンコーディングが一体化している形式」と言えます。これらの形式では、文字をどのようなバイト列で保存するかが直接定義されています。
UTF-8 では、 ASCII 文字(0x00~0x7F)は同じ 1 バイトの形式で表現されるため、既存の ASCII ベースのシステムやデータとの互換性が保たれています。非 ASCII 文字(日本語、中国語、絵文字など)は、コードポイントに応じて 2~4 バイトで表現されます。たとえば、日本語のひらがなは 3 バイト、絵文字は 4 バイトで表現されます。
| 文字範囲(コードポイント) | バイト数 |
|---|---|
| U+0000~U+007F(ASCII) | 1バイト |
| U+0080~U+07FF | 2バイト |
| U+0800~U+FFFF | 3バイト |
| U+10000~U+10FFFF | 4バイト |
現在 UTF-8 は Web やアプリケーションの文字コードの標準として広く採用されています。理由として、 ASCII との互換性、多言語対応が可能な点、データの効率的なエンコーディングが挙げられます。 Web ページの作成で使用される HTML5 では UTF-8 を使用することが推奨されており、 MySQL や PostgreSQL などのデータベースでも UTF-8 がサポートされています。また、 Python 、 JavaScript 、 Java などの多くのプログラミング言語で UTF-8 がデフォルトとして使用されています。
Windows環境における文字コードについて
過去の Windows(特に日本語版)では、 Shift_JIS が日本語環境における主要な文字コードとして採用されていました。特に Windows の日本語版 OS では、日本語入力や表示の互換性を保つために広く使用されており、日本語を扱うほとんどのアプリケーションが Shift_JIS を前提として設計されていました。そのため UTF-8 の採用は進んでいませんでした。しかし Windows 10(バージョン1903以降)および Windows 11 では、システム全体で UTF-8 を使用するオプションが追加されています。
Microsoft Office の Excel や Word などでは UTF-8 で保存・読み込みすることができます。また Windows 標準のメモ帳( Notepad )は、以前は Shift_JIS がデフォルトでしたが、現在の Windows では UTF-8( BOM なし)がデフォルト文字コードとして採用されています。ただし、 UTF-8(BOM付き)や Shift_JIS など他のエンコーディング形式も選択可能です。
ただし、システム全体で UTF-8 を有効にすると、 Shift_JIS など従来の文字コードを前提に設計された古いアプリケーションで文字化けや動作不良が発生する可能性があります。例えば、日本語専用の会計ソフトや旧型の電子メールクライアントなど、 Shift_JIS に依存したアプリケーションでは、このような問題が特に顕著です。こうした場合は、従来の設定を維持するか、対応するアプリケーションのアップデートが必要になる場合があります。
UnicodeとUTF-8の関係について
Unicodeは、英語のアルファベット、日本語の漢字やひらがな、アラビア文字、絵文字など、世界中のほとんどすべての文字に固有の番号(コードポイント)を割り当て、異なる言語間で文字を統一的に扱えるようにするための規格です。コンピュータ上で文字を表現・保存・やり取りするための「共通の基準」を提供し、多言語対応が求められる現代のシステムにおいて不可欠な存在となっています。
Unicodeでは、例えばアルファベットの「A」はU+0041、日本語の「あ」はU+3042といったコードポイントが割り当てられています。ただし、コードポイントは文字を識別するための数値であり、そのまま保存されるわけではありません。コードポイントを直接保存するとデータ量が増えたり、他のシステムとの互換性が損なわれる場合があるため、効率的にバイト列として表現する仕組みが必要です。
そのため、 Unicode ではコードポイントをバイト列に変換するルールを提供するエンコーディング形式が存在します。代表的なものには UTF-8、UTF-16、UTF-32 があります。これらのエンコーディング形式は、コードポイントを効率的に保存・伝送するために異なる方法でバイト列を生成します。
UTF-8 では Unicode のコードポイントを 1~4 バイトで表現します。 ASCII 文字は 1 バイト、非 ASCII 文字は 2~4 バイトでエンコードされます。 Web や多言語対応が求められるシステムで最も広く使用されています。 UTF-16 では Unicode のコードポイントを 2~4 バイトで表現します。 Windows や Java プラットフォームなど、一部のシステムで広く採用されています。 UTF-32 では Unicode のコードポイントを固定長の 4 バイトで表現します。データサイズは大きくなりますが、計算が簡単になるため、内部処理や特殊用途で使用されます。
現在、 UTF-8 は Web やアプリケーションの文字コードの標準として広く採用されています。 UTF-16 や UTF-32 も用途に応じて使用されていますが、多言語対応と効率性の観点から UTF-8 が主流となっています。
HTML文書の中で文字コードを指定するには
HTML で記述した文書をファイルに保存する場合、使用する文字コードとして UTF-8 が推奨されています。ただ他の文字コードを使用することもできます。
HTML 文書の中で使用する文字コードを記述するには <head> 要素の中で <meta> 要素を使って記述します。
<meta charset="文字コード">
例えば文字コードとして UTF-8 を使用する場合は、次のように記述します。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>サンプル文書</title>
</head>
<body>
</body>
</html>
文字コードとして UTF-8 を指定した場合は、 HTML 文書をファイルとして保存するとき、使用する文字コードとして UTF-8 を指定してください。文字コードとして Shift_JIS を指定した場合は、ファイルを保存するときに Shift_JIS を指定してください。
文字化けが発生する原因
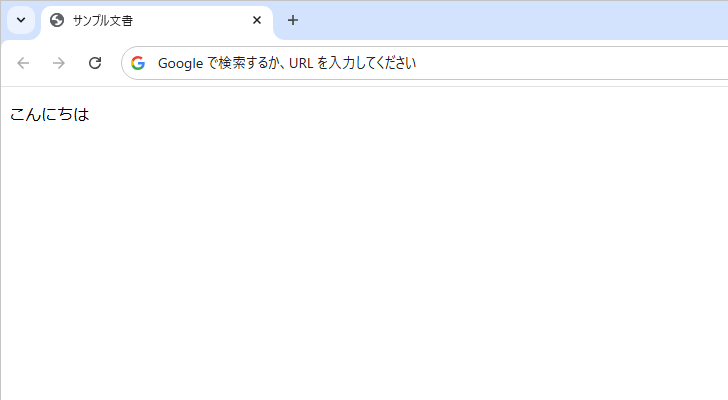
HTML 文書で文字コードとして UTF-8 を使用すると記述し、その文書を UTF-8 を使って保存した場合、問題なく表示されます。例えば下記の HTML 文書を UTF-8 で保存します。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>サンプル文書</title>
</head>
<body>
<p>こんにちは</p>
</body>
</html>
先ほどのファイルをブラウザで表示してみると、問題なく表示されました。
それでは HTML 文書を一部変更し、使用する文字コードとして Shift_JIS を使用すると記述し、その文書を UTF-8 を使って保存します。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="Shift_JIS">
<title>サンプル文書</title>
</head>
<body>
<p>こんにちは</p>
</body>
</html>
先ほどのファイルをブラウザで表示してみると、今度は文字化けが発生しました。
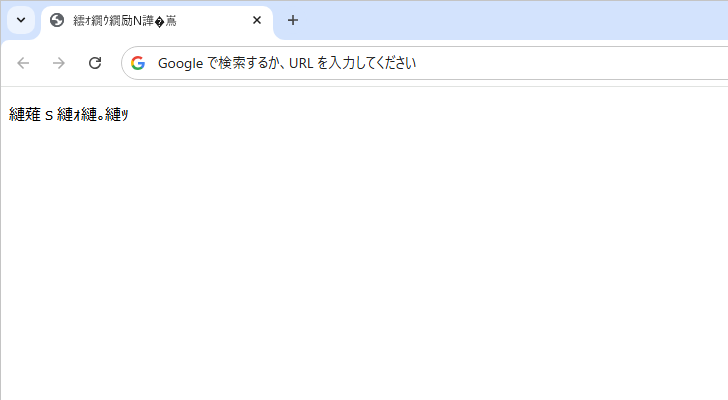
HTML 文書の中で使用する文字コードを Shift_JIS と記述しているので、ブラウザは読み込んだファイルのバイナリデータを Shift_JIS で変換されているものとして文字に戻して表示しますが、実際には UTF-8 を使って保存されていたため正しい文字に変換されずに文字化けしてしまっています。
文字化けを発生させないためには、 HTML 文書の中で使用する文字コードを正確に記述し、実際にそのファイルを保存するときに記述した文字コードを使って保存してください。
-- --
Web ページで使用される文字コードの基本と、文字化けの原因について解説しました。
( Written by Tatsuo Ikura )

著者 / TATSUO IKURA
これから IT 関連の知識を学ばれる方を対象に、色々な言語でのプログラミング方法や関連する技術、開発環境構築などに関する解説サイトを運営しています。