- Home ›
- Perl入門 ›
- Perlにおける正規表現
マッチした文字列の前後を取得する($`, $')
正規表現のパターンが文字列にマッチした場合、マッチした部分だけでなく、マッチした部分の前後の文字列を取得することができます。ここでは Perl の正規表現でマッチした文字列の前後を取得する方法について解説します。
(Last modified: )
マッチした文字列の前後を取得する
パターンにマッチした部分の文字列は特別な変数 $& に格納されますが、マッチした部分よりも前の部分と後の部分をそれぞれ取得することができます。マッチした部分よりも前は特別な変数 $` に格納され 、マッチした部分よりもあとは特別な変数 $' に格納されます。
$` マッチした部分よりも前の部分が格納される $' マッチした部分よりも後の部分が格納される
次の例を見てください。
my $str = "book is 2000yen, cake is 800yen";
if ($str =~ /\d+yen/){
print "マッチした文字列 : $&\n";
}
パターンは \d+yen となっているため数値で構成される文字が 1 文字以上続いたあとに "yen" が続く文字列にマッチします。
マッチが成功した場合、自動的に変数 $& にはマッチした文字列全体が格納されます。今回の場合は "2000yen" です。そして同じように特別な変数 $` にはマッチした文字列より前の部分 "book is " が格納され、また特別な変数 $' にはマッチした部分より後の部分 ", cake is 800yen" が格納されます。
my $str = "book is 2000yen, cake is 800yen";
if ($str =~ /\d+yen/){
print "前の部分 : $`\n";
print "マッチした文字列 : $&\n";
print "後の部分 : $'\n";
}
なお $& と同じように $` と $' も処理効率が悪いと言われています。
それでは簡単なサンプルを作成します。
use strict;
use warnings;
use utf8;
binmode STDIN, ':encoding(cp932)';
binmode STDOUT, ':encoding(cp932)';
binmode STDERR, ':encoding(cp932)';
&check("book is 2000yen, cake is 800yen");
&check("orange is 950yen");
sub check{
if ($_[0] =~ /\d+yen/){
print $_[0]." は /\\d+yen/ にマッチします。\n";
print "マッチした前の部分は $` です。\n";
print "マッチした部分は $& です。\n";
print "マッチしたあとの部分は $' です。\n";
}else{
print $_[0]." は /\\d+yen/ にマッチしません。\n";
}
}
テキストエディタでプログラムを記述したあと sample.pl という名前で保存します。(文字コードは UTF-8 です)。コマンドプロンプトを起動し、プログラムを保存したディレクトリへ移動したあとで次のように実行します。
perl sample.pl
次のように実行結果が表示されます。
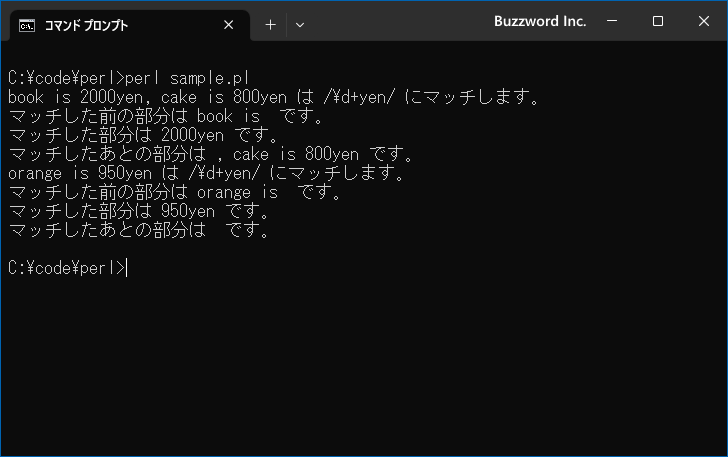
パターンにマッチした部分に加えて、マッチした部分の前の部分とあとの部分をそれぞれ参照し画面に表示しました。
-- --
Perl の正規表現でマッチした文字列の前後を取得する方法について解説しました。
( Written by Tatsuo Ikura )

著者 / TATSUO IKURA
これから IT 関連の知識を学ばれる方を対象に、色々な言語でのプログラミング方法や関連する技術、開発環境構築などに関する解説サイトを運営しています。